
前言&介绍
为什么要在本地部署deepseek模型?
-
由于deepseek之前受到过攻击,官网地址经常会出现无响应的情况,久久不能得到回复,这种结果显然是无法接受的。本地部署可以更好的进行模型的调试和测试,可以更快的得到结果。
-
本地部署可以更好的满足一些特殊的需求,比如:现在有一个电子版的新华字典,可以把它丢给AI学习,后面有问题就可以找AI了。还是诗词这些也都是,想不起来就去早AI就行了。
什么是deepseek模型?
- deepseek是一个基于深度学习的语言模型,可以生成文本。它可以生成的文本可以用来训练机器翻译、文本摘要、文本生成等任务。
- 它是基于开源的transformer模型,可以生成文本,可以生成的文本质量高,生成速度快。
- 它可以生成的文本可以用来训练机器翻译、文本摘要、文本生成等任务。
本地部署
安装OLLAMA
我们需要从OLLAMA上下载并且管理我们的deepseek模型。
OLLAMA可以直接去官网下载,官网地址,也可以去github上下载,github地址,github就是点击release这里下载。
OLLAMA常用指令和配置
|
|
- 后续还需要对ollama进行配置,增加两个环境变量
|
|
- 这里的
/path/to/ollama/models就是你下载的模型的存放路径,比如:E:\ollama\models。
下载deepseek模型
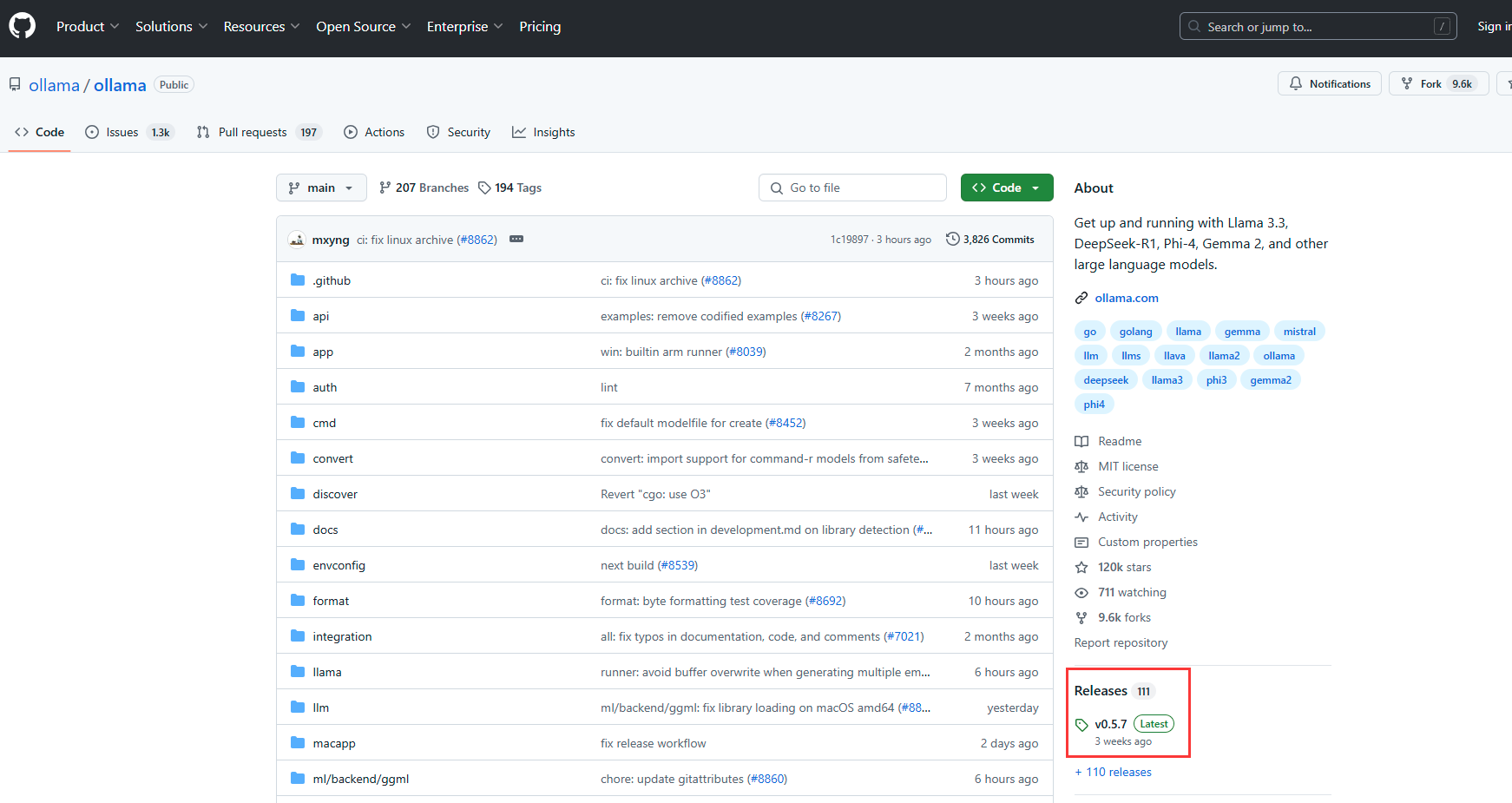
直接在OLLAMA上搜索deepseek就可以找到我们要的模型。 V3和R1,我会直接选择R1,因为我需要他来帮助我进行工作上的需求。
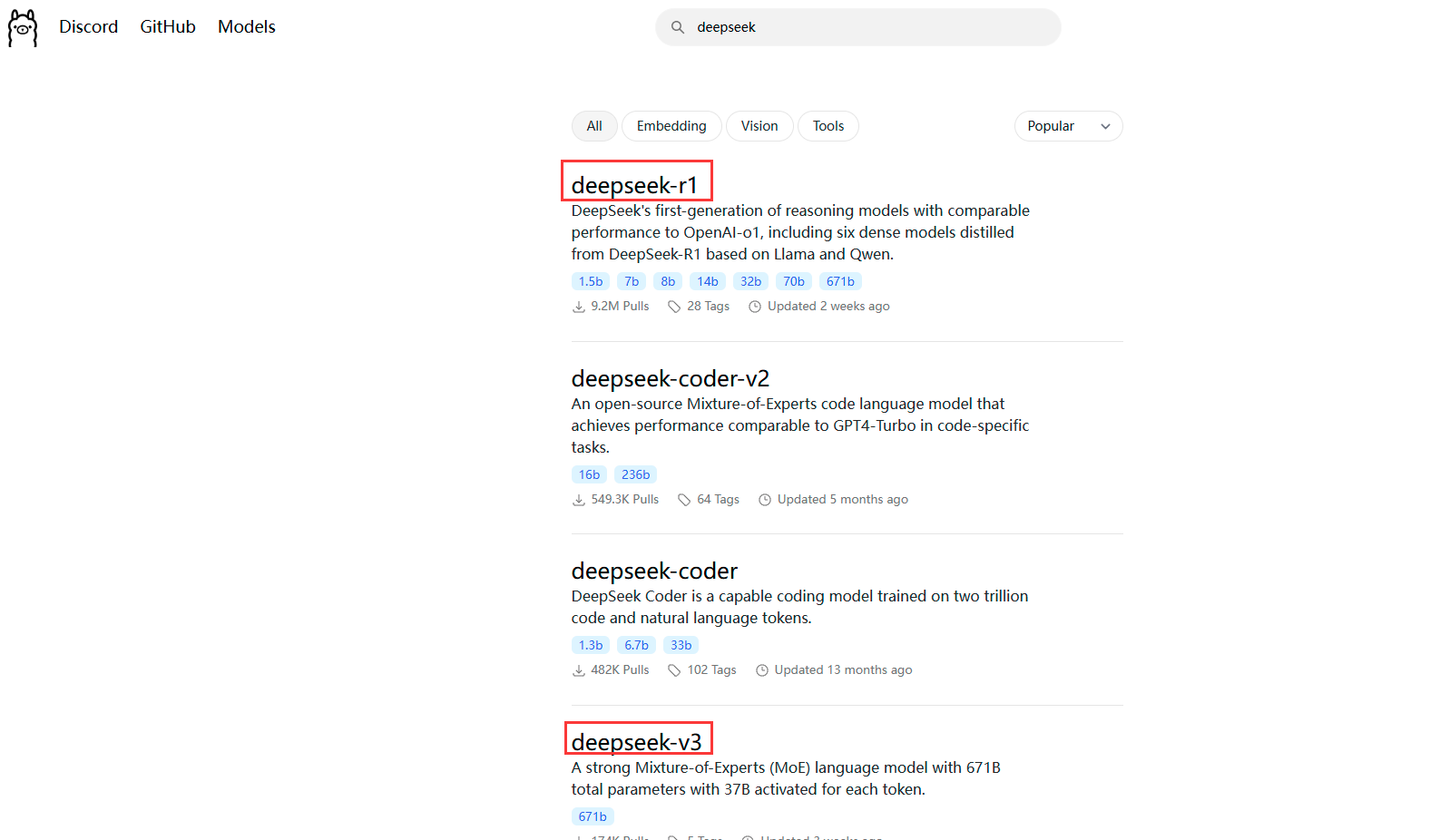

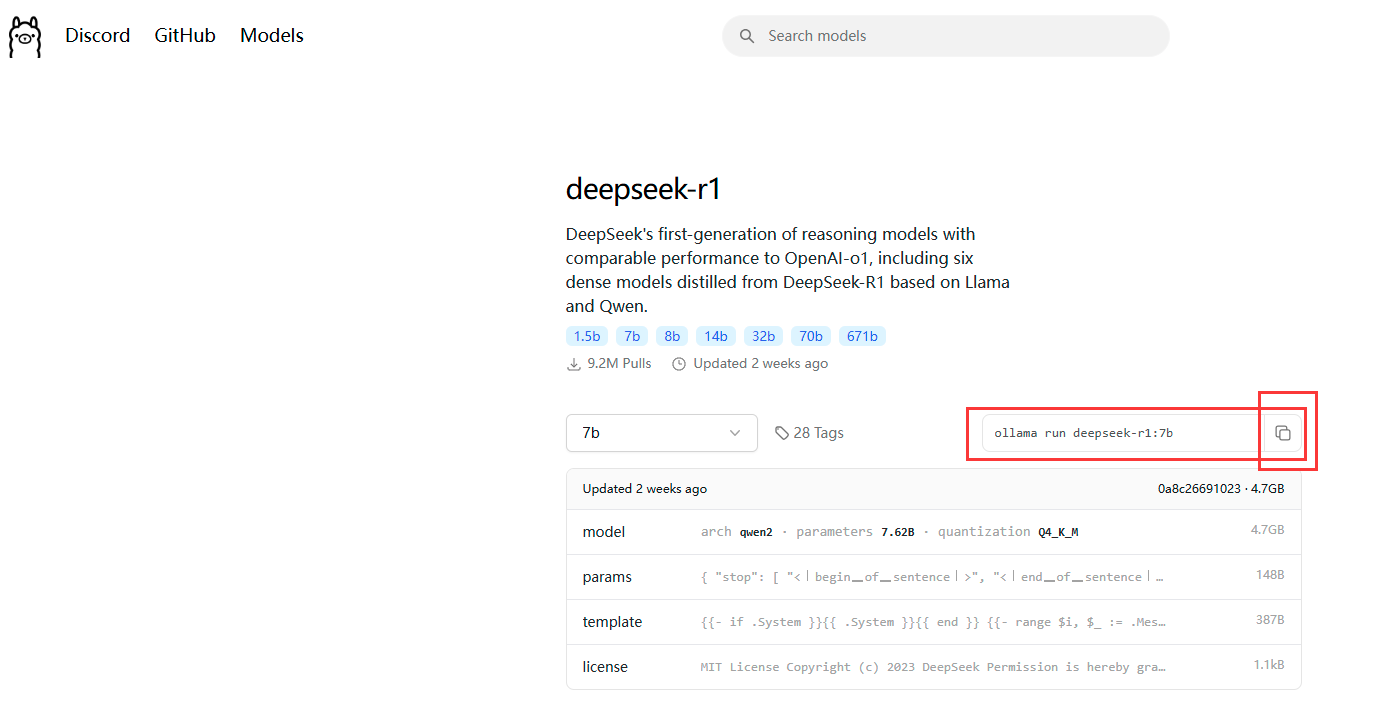
复制下来这个指令,然后在CMD中运行。如果没有下载对应的模型,则会帮你自动下载,如果已经下载好了则是直接运行。然后就可以进行正常的对话了。 回复
/bye就可以结束对话
让deepseek可视化,定制功能
下载RagFlow,安装Docker
我们需要用到RagFlow这个LLM开源框架,github地址。
- 不是一定要用git指令去下载,我们可以直接下载zip压缩包,解压到自己想要的目录即可。
在使用RagFlow之前,我们还需要安装Docker,官网地址。
- 下载好Docker之后,我们还需要进行一点简单的配置(
Docker 无需登录,跳过即可)。 在下面新增一段内容:1 2 3 4 5 6 7 8 9 10 11 12{ "builder": { "gc": { "defaultKeepStorage": "20GB", "enabled": true } }, "experimental": false, "registry-mirrors": [ "https://hub.rat.dev" ] } - 下面的
registry-mirrors是新增的镜像源地址,防止访问不到国外源。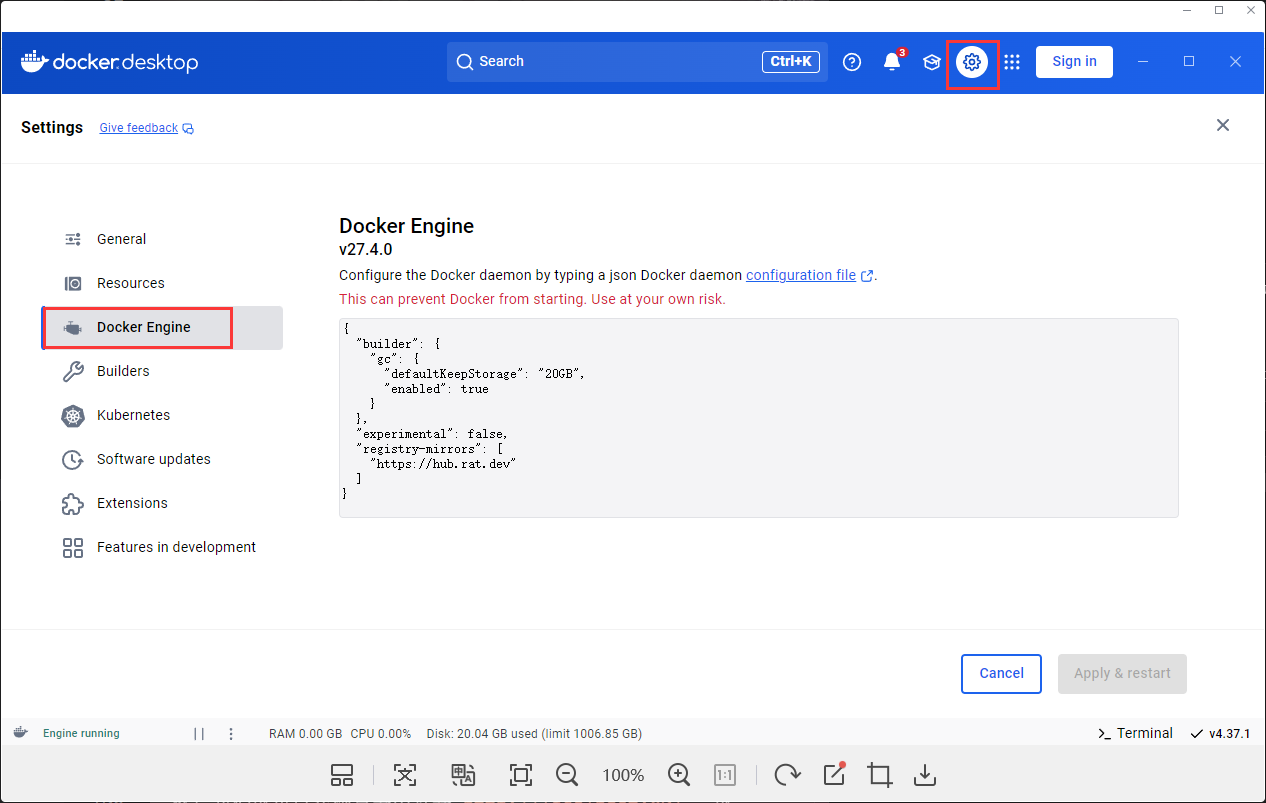
启动RagFlow
把RagFlow解压到自己想要的目录,然后进入到RagFlow目录
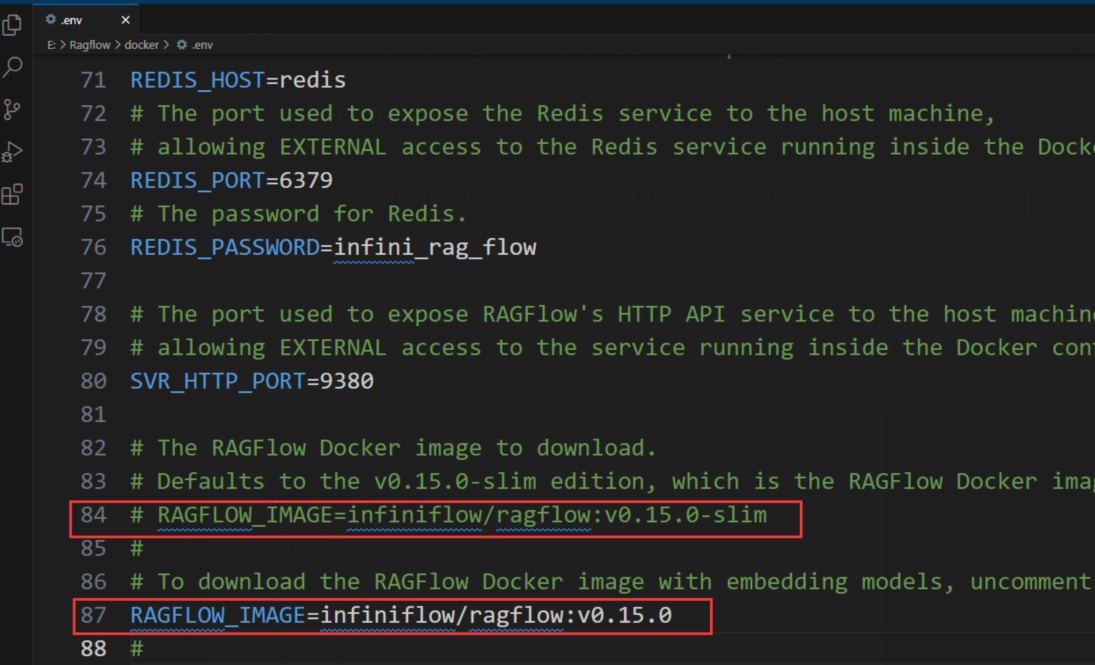
启动之前先修改一下设置,完整版的功能更加强大一些。
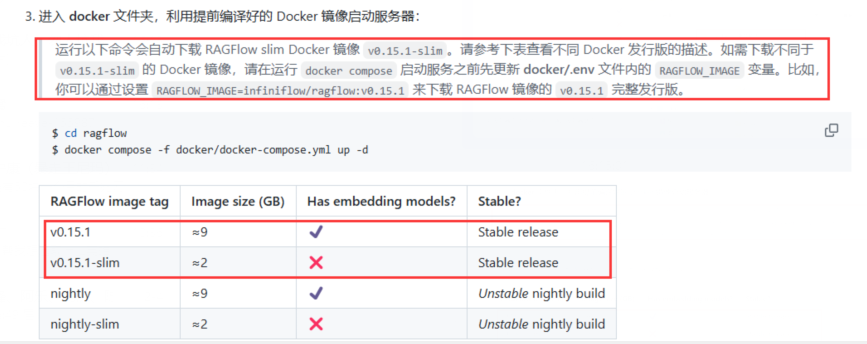
之后就可以在RagFlow目录下打开CMD,输入以下指令启动RagFlow。
|
|
首次启动应该会有一个拉取过程,需要几分钟时间。
然后我们就可以在浏览器中打开
http://localhost:80/,就可以看到RagFlow的界面了。
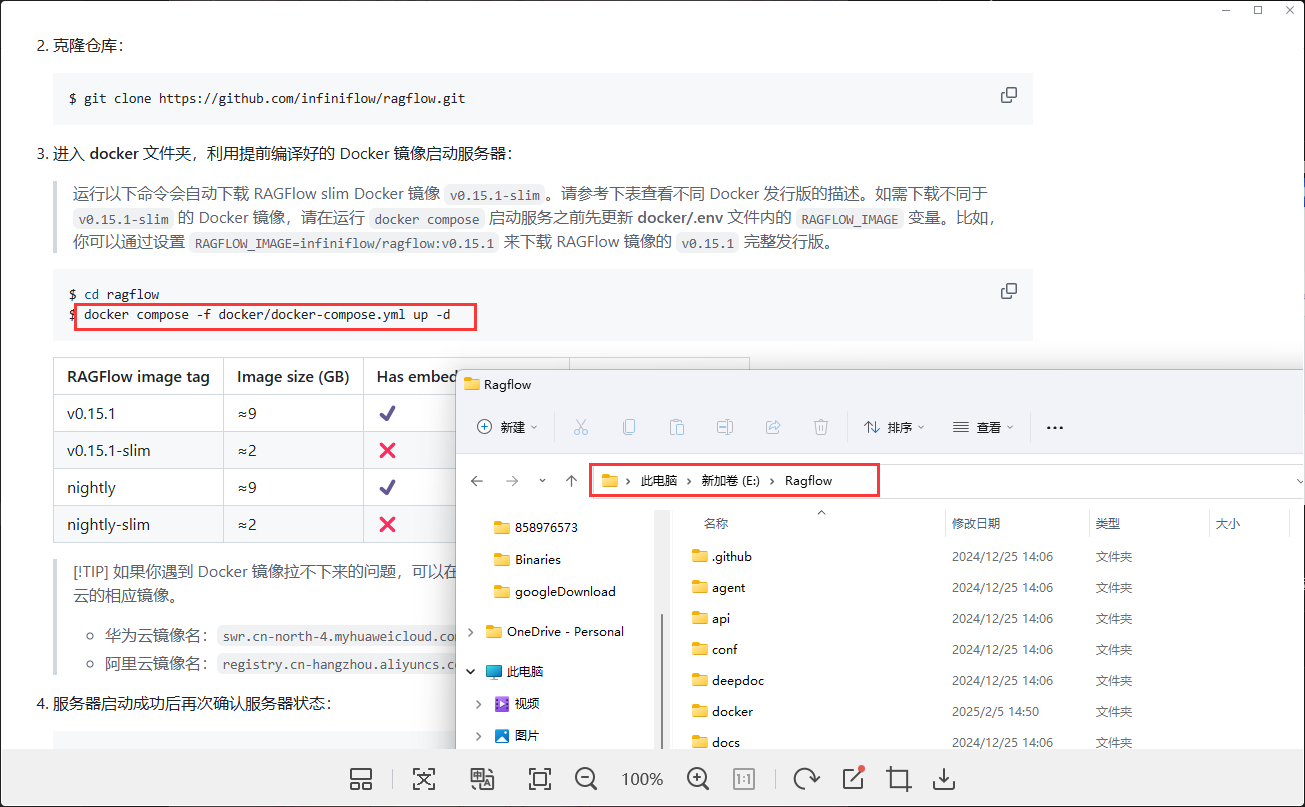
手动下载zip可以免去git下载的过程,,手动进入RagFlow目录打开CMD运行指令即可。
RagFlow的使用
首次进去需要注册账号,账号都是存在本地的,无需担心泄密问题,首个注册账号的人将会自动成为管理员。
添加模型
点击自己的头像,然后点击左侧模型提供商。找到OLLAMA并且点击下面的添加模型,由于我已经添加过了,OLLAMA会在上面,如果没有添加过的话,OLLAMA会在下面
(请把下面的ZHIPU-AI当做OLLAMA即可)。
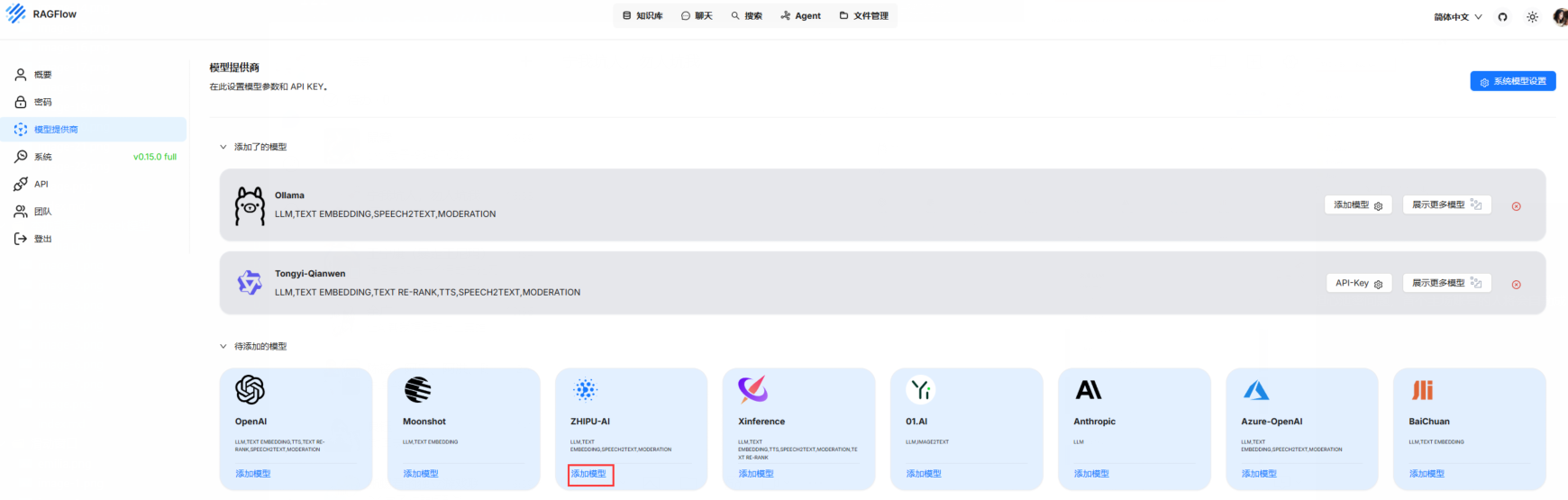
这里填的时候要注意一下,模型名称必须和OLLAMA LIST中显示的一致。 下面的这个基础URL,把localhost换成自己的IPV4地址即可,不换应该也可以添加成功,后面的11434端口是我们之前配置的环境变量,如果出现无法添加的情况,请检查一下这个环境变量是否正确。
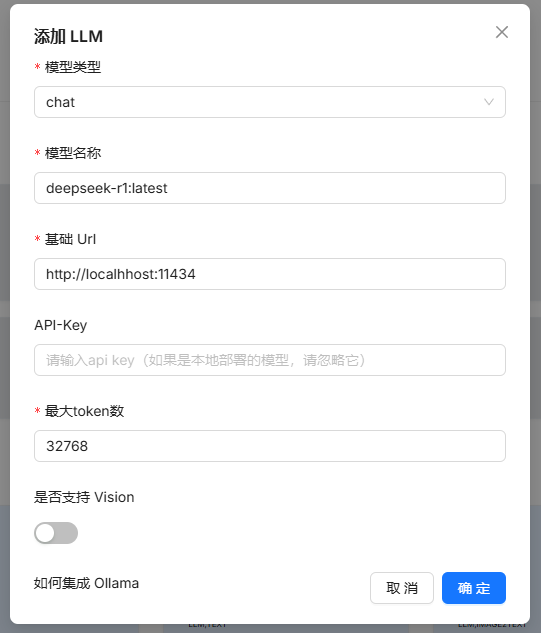
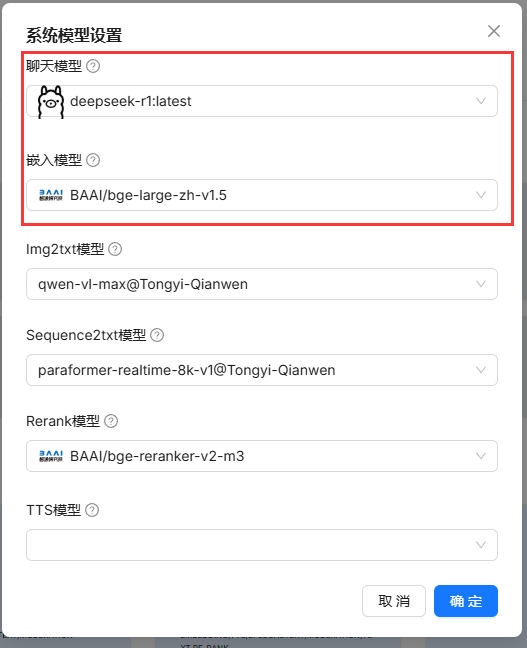
模型添加完毕之后也要改一下系统模型设置(右上角那个蓝色按钮)
添加知识库
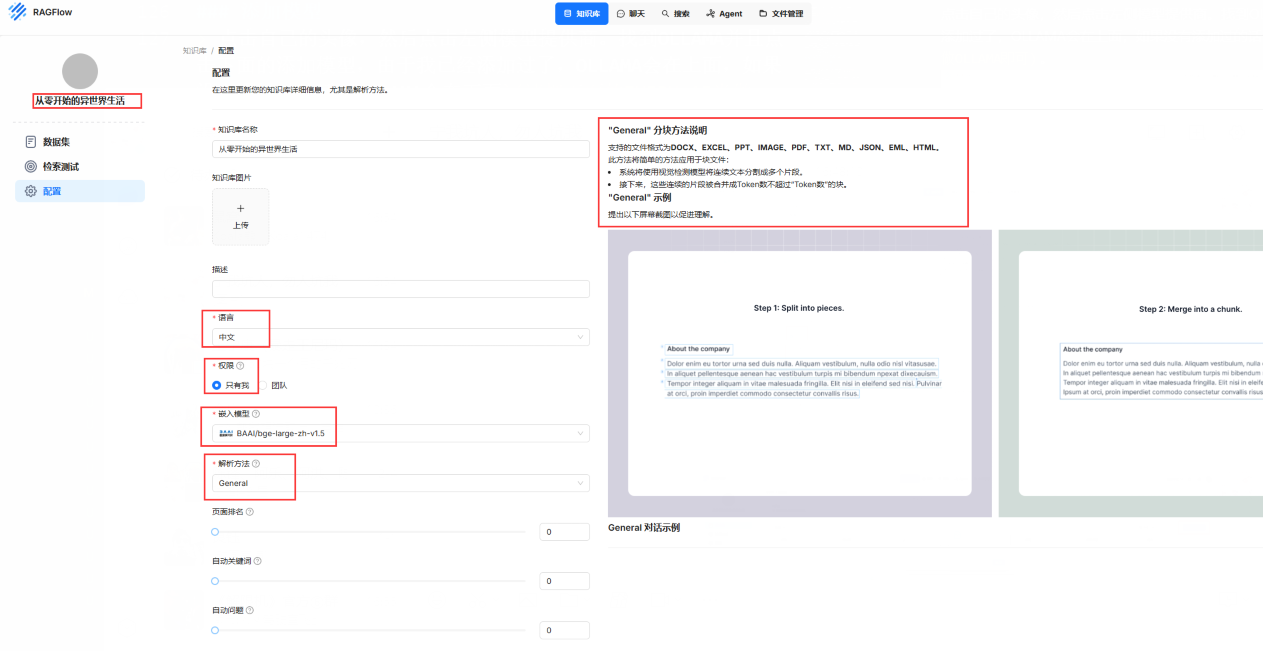
构建知识库 添加知识库的时候,要注意一下语言和权限,还有注意解析方法,可以根据文件的类型选择不同的解析方法。
之后是添加文件内容,可以添加多个文件,也可以添加文件夹,RagFlow会自动递归查找。
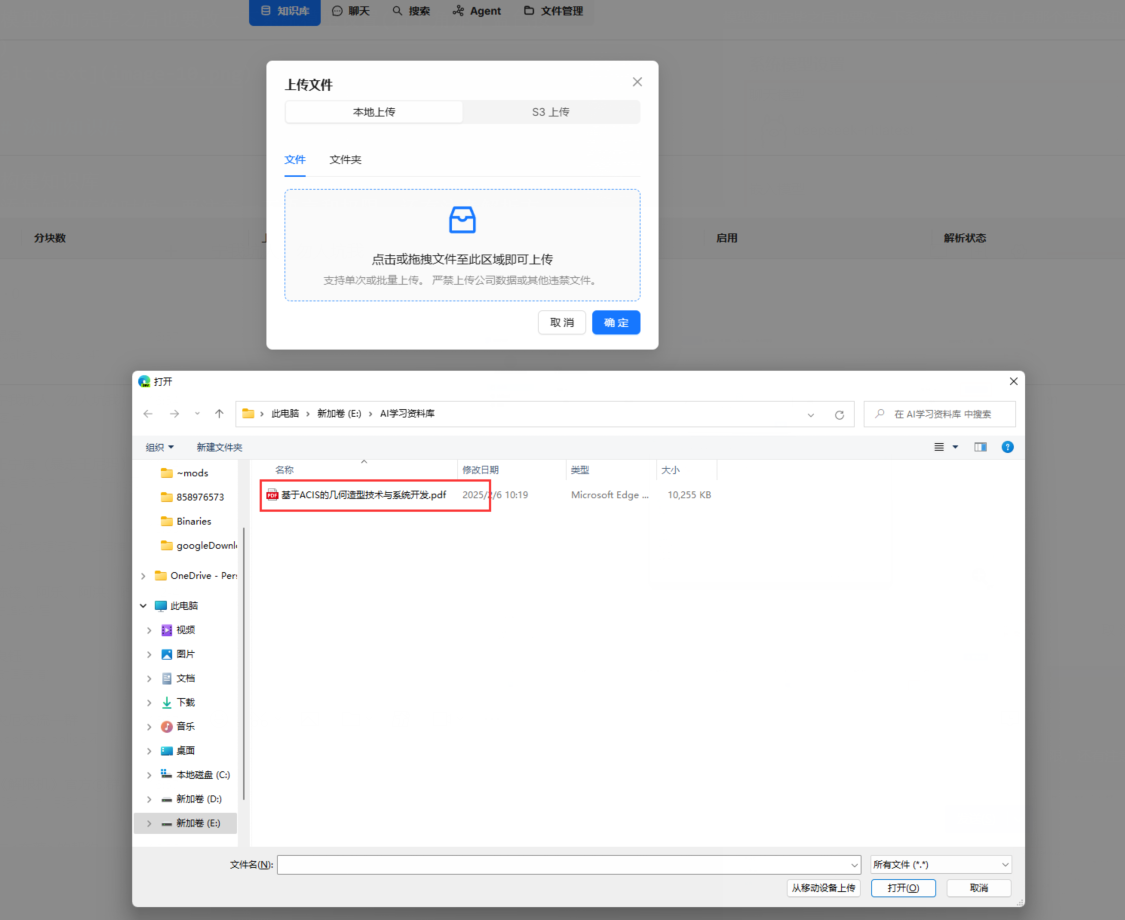
如果是未解析状态,还需要自己去解析

对话
对话必须用到知识库,所以可以等到知识库解析完毕之后再去对话。这几个设置我也不是完全了解,就不多介绍了。
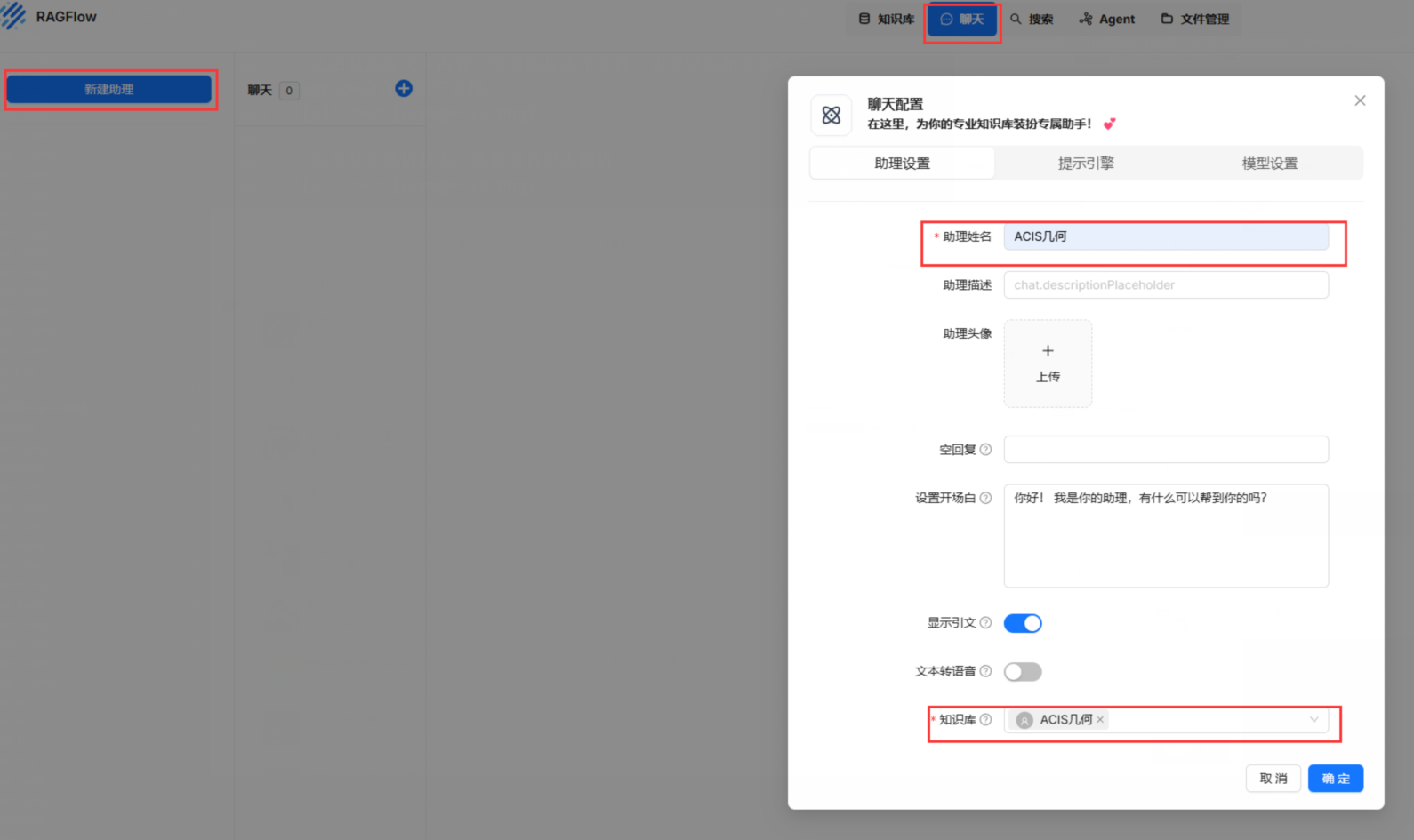
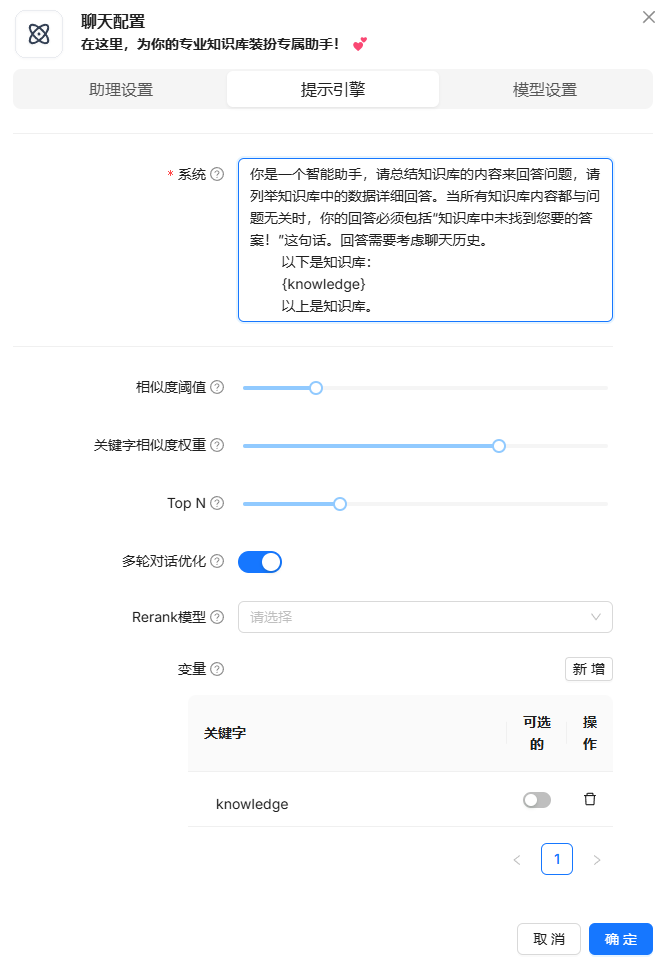
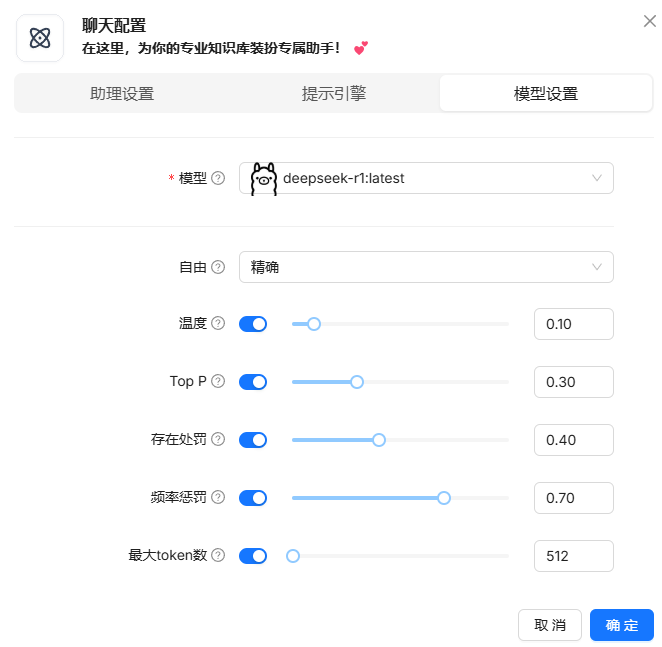
对话效果
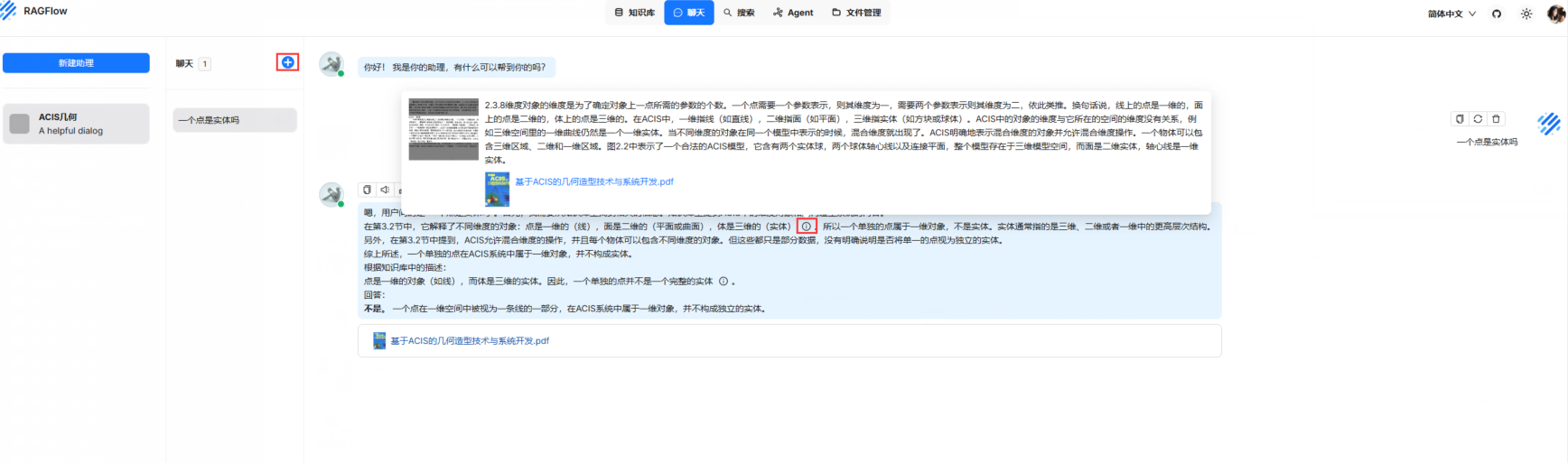
其他
安装完OLLAMA,把模型下载到本地之后就可以进行对话了,如果这个文档有什么不清楚的地方,就可以找AI问,AI可以进行辅助解答。